FOR UMIDDELBAR UTGIVELSE nr. 3112
Denne teksten er en oversettelse av den offisielle engelske versjonen av pressemeldingen, og den er kun ment som et praktisk referanseverktøy. Du finner detaljene og spesifikasjonene i den originale engelske versjonen. Dersom tekstene ikke stemmer overens, er det den originale engelske versjonen som gjelder.
Mitsubishi Electric separerer simultantale fra flere ukjente personer som er tatt opp med én mikrofon
Talesepareringsteknologi er oppnådd ved hjelp av merkevarebeskyttet «Deep Clustering»-metode (dyp gruppering)
TOKYO, 24. mai 2017 – Mitsubishi Electric Corporation (TOKYO: 6503) kunngjorde i dag at de har utviklet den første teknologien i verden som separerer, og deretter rekonstruerer i høy kvalitet, simultantale fra flere ukjente personer tatt opp med én enkelt mikrofon i sanntid. I tester har simultantale fra to og tre mennesker blitt separert med opptil henholdsvis 90 og 80 prosent nøyaktighet. Selskapet mener at de er de første i verden som har oppnådd dette på tidspunktet for kunngjøringen. Den nye teknologien ble utviklet ved hjelp av Mitsubishi Electrics merkevarebeskyttede «Deep Clustering»-metode (dyp gruppering), som er basert på kunstig intelligens (AI), og det forventes at teknologien skal bidra til mer forståelig talekommunikasjon og mer nøyaktig talegjenkjenning.
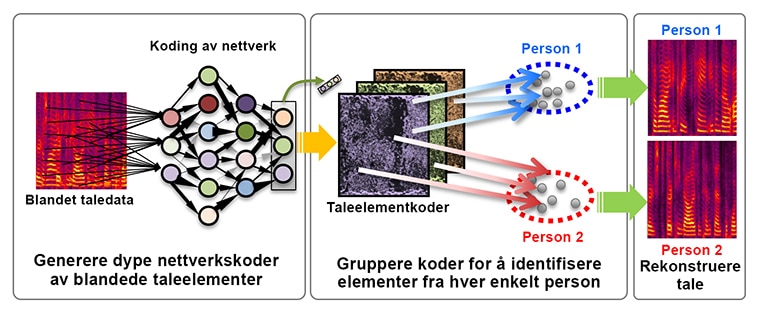
Når to personer snakket samtidig, var nøyaktigheten på over 90 prosent, noe som er tilstrekkelig for kommersielle bruksområder, sammenlignet med en nøyaktighet på 51 prosent ved bruk av konvensjonell teknologi. Den nye teknologien er i stand til å skille mellom kombinasjoner av flere ulike språk og kjønn. Resultatene ovenfor er basert på ideelle opptaksforhold, som lavt støynivå fra omgivelsene og personer som snakker med omtrent samme volum.
Deep Clustering-teknologien tar i bruk Mitsubishi Electrics merkevarebeskyttede Deep Learning-metode (dyp læring) for å lære å kode signalkomponenter i de opprinnelige taledataene fra flere personer, slik at signalkomponentene til hver enkelt person lett kan gjenkjennes av kodene. For å oppnå dette blir kodingen optimalisert, slik at ulike signalkomponenter som tilhører samme person har lignende koder, og signalkomponenter som tilhører forskjellige personer har ulike koder. Den lærte kodetransformeringen brukes på den innkommende talen, og kodene til hver enkelt persons signalkomponenter identifiseres ved hjelp av en grupperingsalgoritme som prosesserer datapunkt inn i grupper basert på likhet. Hver enkelt persons tale rekonstrueres ved å sammenføye de separerte talekomponentene.
Nøyaktighet ved separering av simultantale fra flere personer*
| To personer (én mikrofon) | Tre personer (én mikrofon) | |
|---|---|---|
| Ny teknologi | > 90 % (først i verden) | > 80 % (først i verden) |
| Konvensjonell teknologi | 51 % | – |
*Basert på ideelle opptaksforhold
Merk at pressemeldingene er riktige på publiseringstidspunktet, men de kan endres uten varsel.